

{kind=link}

The emergence of generative artificial intelligence has incited a well-coordinated global opposition. This phenomenon is not merely a passing cultural trend or simple resistance; rather, it represents a sustained response to transformations in the job market, power structures, identity, and physical environments. Historically, anti-technology movements have been associated with specific contexts, such as anarchism and eco-extremism. However, the extensive societal changes induced by generative AI have broadened these concerns, bringing together professional groups, labour unions, civil rights advocates, and environmental organisations to actively resist the AI technology. This movement furthers enduring political tension and economic division.
The anti-AI movement is centred on three primary concerns: economic displacement, algorithmic control and existential threats. Economic concerns arise from the utilisation of human intellectual labour without consent; wherein generative models are trained on human creativity to automate and devalue creators. This has prompted collective action and resistance in the workplace. Concurrently, political opposition is directed towards algorithmic control, as evident in predictive policing, automated sorting, and AI-driven surveillance. Such overreach has reduced trust in institutions, as exemplified by the Dutch government’s resignation in 2021 following an automated system’s erroneous accusations of fraud against families in the Netherlands. Furthermore, organisations such as stop AI perceive artificial general intelligence as a threat to human survival, aligning with climate activism movements such as Extinction Rebellion. This apprehension is aggravated by the local impacts of AI infrastructure, including the substantial consumption of electricity and water by data centres and the deployment of automated systems in war zones. To counter these developments, the movement operates across economic, political and cultural domains, each with distinct methods and historical contexts. This resistance goes beyond mere rhetoric and employs sophisticated technical measures at the software and network levels.
Technical Mechanics of Adversarial Software and Data Poisoning

The technical dimension of the anti-AI movement concentrates on adversarial software engineering to disrupt data scraping and safeguard human work. Tools such as Glaze and Nightshade, developed by the SAND Lab at the University of Chicago, employ mathematical modifications to exploit the vulnerabilities of deep learning models.
Glaze is engineered to safeguard an artist’s distinctive style from replication by generative models. It achieves this by optimising multiple objectives to set up minimal visible alterations while modifying the interpretation of the image by neural networks. This is done by introducing a slight modification to the original image, ensuring that the altered image features align with a target style from a different genre, while the change remains imperceptible to the human eye. Consequently, when an AI model attempts to learn from a glazed artwork, it misinterprets the style, resulting in an inaccurate style imitation. Conversely, Nightshade functions as an offensive tool for training-time attacks, operating similarly to a neural Trojan by embedding corrupted data into extensive datasets collected by web scrapers. Nightshade modifies the mathematical features of an image so that the model associates the text prompts with unrelated concepts. For instance, if a model is trained on Nightshade-protected images labelled as “cow”, it may associate “cow” with the features of a “handbag”, leading to the generation of handbag images when prompted for a cow, thereby disrupting the model’s comprehension.
Despite the widespread adoption of Glaze and Nightshade, which have been downloaded over nine million times, research has identified substantial vulnerabilities in local mathematical poisoning. At the 34th USENIX Security Symposium in August 2025 in Seattle, researchers introduced LightShed, a framework designed to counter these countermeasures. Developed by researchers from the University of Cambridge, Technical University Darmstadt, and the University of Texas at San Antonio, LightShed employs a three-step process. Initially, it detects known poisoning alterations in images with 99.98% accuracy. Subsequently, it reverse-engineers the mathematical signature of the change using public data. Finally, it eliminates the adversarial noise and restores the image for model training.
Furthermore, poisoning tools are heavily reliant on architecture, with most being optimised for older systems, such as Stable Diffusion 1.4 or 1.5, which utilise single CLIP text encoders. Modern systems equipped with dual text encoders or comprehensive Large Language Models exhibit greater resistance to these modifications. In addition, developers can readily remove adversarial noise using straightforward denoising techniques or image preprocessing during data curation.
Network-Edge Defences and Crawl Control Infrastructures
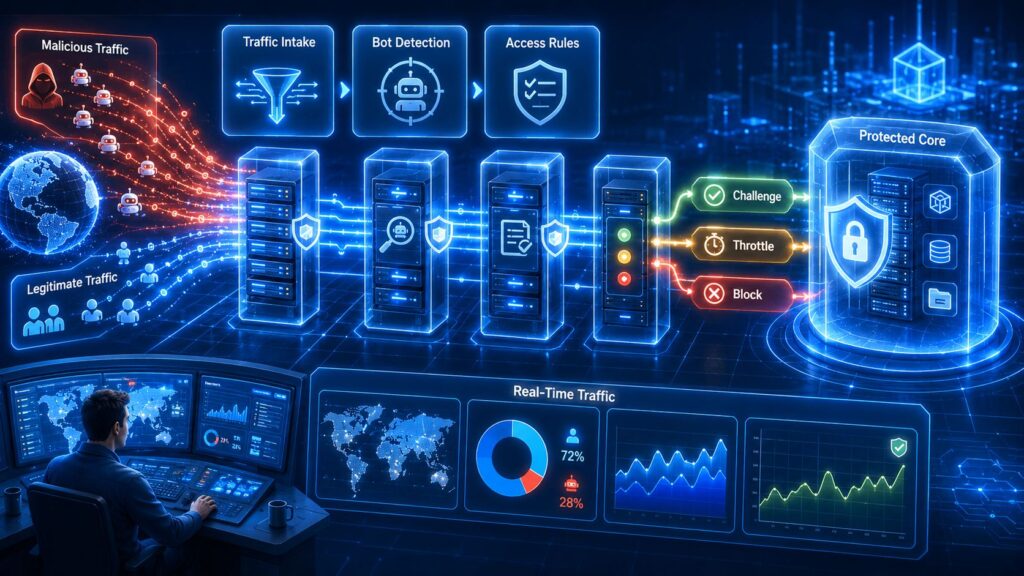
Owing to the technical limitations of local mathematical poisoning, efforts have been made to transition to edge-routing infrastructure to regulate the original content. Platform operators and web hosts employ advanced network configurations to enforce data governance policies at the gateway.
Cloudflare has developed an extensive suite of tools designed to manage and control automated scraping. These tools can identify, redirect, or halt such activities. The system utilises Cloudflare’s verified bot database, which distinguishes known AI training crawlers, such as GPTBot, ClaudeBot, and Bytespider, from standard search engine indexers. For verified bots, Cloudflare offers Redirects for AI Training, which enforce specific policy mechanisms. This mechanism ensures that crawler’s access only updated and designated data, thereby preventing them from scraping outdated or non-canonical content. For sites wishing to completely opt out, Cloudflare’s Managed robots.txt and Content Signals Policy provide a clear framework. These tools, employed by over 3.8 million domains, automatically incorporate machine-readable directives into the host robot. txt file. The Content Signals Policy outlines three categories of computational use: search, for traditional search indexing; ai-input, for real-time query inference; and ai-train, for content ingestion for model training or for fine-tuning. When crawlers disregard these directives, platform hosts can employ active defence measures via a web application firewall. With Cloudflare Turnstile, hosts can challenge unverified crawlers with silent cryptographic human-verification tests, effectively halting unauthorised automated traffic without impacting users. Additionally, operators deploy AI Labyrinths, which are web traps designed for noncompliant crawlers. Once a scraper is identified as violating the site’s robots.txt directives, the edge server ensnares the bot in a maze of nonsensical content and endless circular links. This tactic consumes the crawler’s bandwidth, slows its servers, and feeds useless data back into its training repository, thereby increasing the cost of unauthorised data scraping.
Implementing anti-AI strategies involves trade-offs, providing protection for creators and workers while introducing technical and commercial limitations.
An Analysis of Generative AI Dependency

The anti-AI movement is driven by an increasing apprehension and opposition to society’s transition towards a reliance on Generative AI. As both individuals and industries increasingly depend on AI for content creation, the backlash grows stronger due to the economic, cultural, and cognitive impacts that follow.
The emergence of generative artificial intelligence (AI), particularly large language models (LLMs), has resulted in a shift from task execution to the delegation of cognitive functions. It poses a threat by permanently altering human neural pathways, diminishing critical thinking, and fostering widespread intellectual complacency.
The biological processes involved in delegating mental tasks to external devices are observable through neuroimaging. In a controlled study conducted by researchers at the Massachusetts Institute of Technology (MIT) Media Lab, 54 participants aged 18 to 39 were divided into three groups to write essays on standardised scholastic topics such as the ethics of philanthropy and the complexities of choice. Utilizing electroencephalography (EEG) to monitor 32 different brain regions, the study revealed that participants using ChatGPT exhibited significantly lower neural connectivity, particularly in the alpha, theta, and delta frequency bands. These neural networks are essential for creative thinking, memory retrieval and semantic processing. In contrast, the “brain-only” group, which did not employ AI, demonstrated strong, highly integrated frontal-to-posterior neural pathways, indicative of deep engagement and active problem solving.
This cognitive disengagement has serious implications for both learning and memory. While 89% of the brain-only writers could recall specific structural quotes from their essays immediately after writing, a notable 83% of the generative AI users could not remember a single phrase of their synthetically generated content. By circumventing the neurological resistance encountered when grappling with complex ideas—AI users completed tasks efficiently but failed to incorporate any of the information into long-term memory networks. Furthermore, prolonged reliance on such systems results in cognitive debt, where the lack of mental exercise limits the brain’s natural neuroplasticity, leaving individuals unprepared to address new problems independently.
The decline in human judgment is worsened by automation complacency, a behavioural shift characterised by decreased vigilance and critical oversight as trust in automated systems increases. This phenomenon is driven by mental shortcuts rather than mere operational laziness and is highly prevalent, even among highly motivated and experienced professionals.
Complacency is intricately linked to automation bias, wherein individuals tend to prioritise the recommendations of automated systems over conflicting empirical evidence. This issue can be categorised into errors of omission and commission, both of which undermine professional autonomy and judgment. When an AI system is perceived as highly reliable, professionals may lower their safety standards. This is particularly risky with “black-box” systems, where the rationale behind the output is opaque. As disease patterns, regulations, and engineering standards evolve, professionals who excessively rely on historical AI data may fail to identify systemic issues, leading to errors and diminishing their decision-making capabilities.
Recent studies on knowledge workers have revealed a complex interplay between self-confidence, trust in AI systems, and critical thinking. Research involving 319 knowledge workers across 936 real-world scenarios indicates that high trust in AI competence correlates with reduced cognitive effort in evaluating its output. When users perceive AI as infallible, they may misconstrue minor changes in output as genuine analyses. Conversely, workers with high self-confidence in specific tasks exhibit greater critical scrutiny, actively verifying sources and integrating responses rather than uncritically accepting them. This reliance on AI has transformed white-collar work, shifting roles from active task execution to passive management. Instead of gathering information, evaluating evidence, and formulating unique arguments, workers now expend mental energy on prompting, reviewing, and synthesising AI content. This shift results in mental fatigue from managing multiple streams of AI work, with only 36% of professionals actively employing critical thinking to mitigate AI-related risks such as algorithmic errors. Consequently, organisations encounter a situation where diverse professionals produce standardised, unoriginal outcomes for complex problems, thereby limiting innovation and diversity.
The risk of cognitive decline varies with age and education. Younger individuals, particularly those aged 17–25 years, exhibited the highest dependence on AI tools and the lowest unassisted critical thinking scores. This is a concern for developmental cognitive psychologists, as core reasoning skills are still maturing during this period. When students habitually seek direct answers from AI tools instead of using them to support their learning, they forgo the neurological development necessary for abstract reasoning and problem-solving.
Legal Precedents and the Regulatory Front

The conflict between generative AI development and the anti-AI movement has reached courtrooms and legislative assemblies, influencing copyright, contracts, and likeness laws. Litigation in 2025 and 2026 transitioned from abstract fair-use debates to intense contract disputes and substantial licencing settlements. The most notable case is Bartz v. Anthropic, which culminated in a $1.5 billion class-action settlement. The plaintiffs demonstrated that Anthropic trained its models on pirated works from shadow libraries such as Library Genesis and Pirate Library Mirror. Rather than defending fair use, the risk of significant statutory damages prompted Anthropic to settle, paying approximately $3,000 for each of the 482,460 copyrighted books downloaded from the Internet Archive. This established a clear precedent: while training on open-web datasets may claim fair use, utilising pirated database mirrors constitutes a direct copyright infringement.
Simultaneously, in Kadrey v. Meta Platforms has advanced a fourth amended complaint emphasising Meta’s extensive dissemination of copyrighted content. If the court determines that Meta actively downloaded pirated materials during its data collection, the company may incur substantial penalties, akin to the Anthropic settlement. In Europe, the Munich Regional Court has adjudicated multiple cases concerning the legality of AI training practices. In Penguin Random House v. OpenAI, initiated on 27 March 2026 contended that an AI model’s memorisation and reproduction of copyrighted texts constitute unauthorised reproduction and public distribution. Furthermore, the German music-collecting society GEMA is pursuing legal action against Suno Inc. which seeks clarity on copyright liability for generative music models in Europe.
The protection of creative work has also been extended to contract law. In DJV e.V. v. Süddeutsche Zeitung GmbH, filed on 16 April 2025 journalists successfully contested contract terms that compelled them to grant AI training rights to publishers without additional compensation, with the court deeming these terms invalid under the German fair contract standards.
Biometric Likeness and Voice Protections

To address the proliferation of deepfakes and unauthorised digital cloning, state legislatures have enacted specific likeness protection laws. Tennessee is at the forefront with the Ensuring Likeness Voice and Image Security (ELVIS) Act, which is effective from July 2024. The ELVIS Act revises the state’s Personal Rights Protection Act of 1984—originally established by the Elvis Presley estate to manage posthumous likeness rights—by incorporating “voice” as a protectable and inheritable property right. The Act defines three distinct causes of action, imposing both civil and criminal liabilities. It prohibits the unauthorized commercial use of an individual’s name, photograph, voice or likeness. Significantly, the ELVIS Act criminalises the distribution of cloning algorithms or software primarily designed to replicate a person’s voice or likeness without consent, categorising such violations as Class A misdemeanours punishable by up to 11 months and twenty-nine days in jail. California has implemented analogous measures through Assembly Bill (AB) 2602 and Assembly Bill (AB) 1836. Reflecting the protections secured during the 2023 SAG-AFTRA strike, AB 2602 mandates that employers explicitly negotiate the rights to create an AI-generated digital replica of a performer, including a comprehensive description of the intended use. AB 1836 extends these protections posthumously, safeguarding deceased performers from unauthorised digital replication by their estates. These state laws have prompted federal legislative initiatives, including the bipartisan Nurture Originals, Foster Art, and Keep Entertainment Safe (NO FAKES) Act and the No Artificial Intelligence Fake Replicas and Unauthorised Duplications (No AI FRAUD) Act, which seek to establish a consistent national property right over digital replica voices and likenesses.
The EU AI Act 2026 and Extraterritoriality
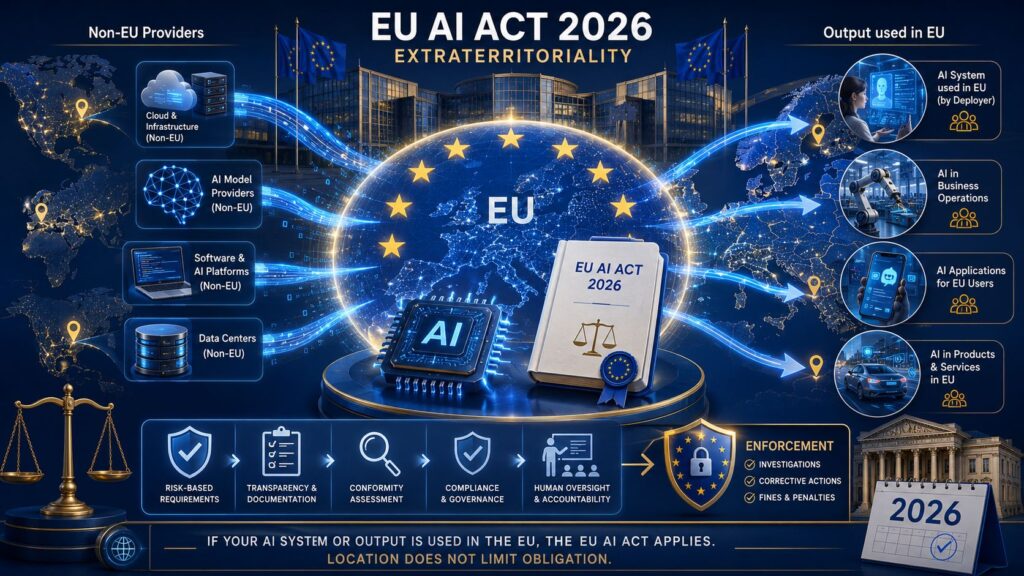
With the implementation of the EU AI Act in 2026, regulatory compliance in Europe has become more stringent. From this year, developers of general-purpose AI models in the EU will be mandated to publish a public summary of their training datasets, adhere to copyright regulations, and employ automated watermarking for synthetic content. The Act’s Code of Practice on Transparency obliges developers to provide metadata indicating AI generation and offers free verification APIs to the public. The geopolitical ramifications of these regulations were amplified on 10 March 2026 when the European Parliament adopted a Resolution on Copyright and Generative Artificial Intelligence. Although not legally binding, this resolution proposes a significant shift in the territorial application of copyright law. Traditionally, copyright has been strictly territorial, permitting developers to train models in regions with lenient regulations, such as the United States or Asia, to circumvent European liabilities. The JURI committee report from the Parliament recommends that EU copyright rules should apply whenever an AI model is available or utilised in the EU market, irrespective of its training location. To enforce this, lawmakers have proposed a flat-rate copyright fee of 5% to 7% of the global turnover for non-compliant developers, along with a presumption of copyright infringement if developers fail to submit a detailed list of training data to the European Union Intellectual Property Office (EUIPO). This extraterritorial objective compels international tech companies to align their global training processes with European standards or risk exclusion from the EU market.
As generative models increasingly produce synthetic text, music, and imagery, the market is transitioning towards a “Human Premium” content economy. In this emerging context, verified human authorship is becoming a valuable trust indicator. To formalise this market, various certification schemes have been established to verify human-created content, like fair-trade labels in physical supply chains. The most notable blockchain-supported platform is AI-Free Cert, which enables creators to declare their work using the MindStar Standard. This self-certification process generates a Certification of Conformity recorded on the Polygon blockchain with a cryptographic SHA-256 proof hash, ensuring a tamper-proof and globally verifiable record of the human origin. Creators pay a fee starting at $0.50 per certificate to download digital badges with embedded verification QR codes, which they can display on their portfolios, galleries, and publications. In contrast, Proudly Human, an auditing firm in Australia, rejected self-certification in favour of a comprehensive verification process. Proudly Human auditors conduct thorough checks throughout the entire lifecycle of a creative work, examining revisions from the initial drafts to the final product. The firm has partnered with major traditional publishing houses to audit and certify works across literature, music, and photography, ensuring a genuine human origin. Despite these efforts, defining what qualifies as “human-made” presents a complex technical challenge. Given that AI capabilities are deeply integrated into everyday systems, office software, and creative tools, defining a clear boundary between use and non-use is practically unfeasible for many users.
Under the MindStar Standard, fundamental tools such as spell check, colour correction, and audio levelling are permissible. Nevertheless, the generation of creative ideas and their implementation must be exclusively human-driven, explicitly excluding generative models that produce outputs from text prompts. Sustaining this standard necessitates continuous financial investment to update verification protocols as software suites incorporate increasingly advanced generative features.
Legal Deposition and Transcription Industry

The “Human Premium” is already contributing to economic disparities across various professional sectors, as businesses and consumers incur higher costs for verified human interaction. In the legal deposition and transcription industry, automated platforms such as Sonix and Otter.ai provide inexpensive, rapid, AI-generated drafts. However, high-stakes litigation continues to depend on certified human transcriptions. Services such as SpeakWrite guarantee 100% human-produced transcripts with a 99% accuracy rate, while Verbit employs AAERT-certified human reviewers trained to meet official court standards. These companies advocate for human-only verification as an essential security feature, charging significantly more than for automated alternatives.
Language Education

Similarly, in language education, platforms such as EngVarta position themselves against automated AI tutors. EngVarta offers one-on-one, voice-only sessions with certified human experts, emphasising real-time corrections and cultural awareness. Furthermore, high-end consumer sectors regard human interaction as a luxury. While standard customer onboarding is increasingly automated through chatbots, companies offer real-time human onboarding as an exclusive high-tier service. In a market saturated with synthetic outputs, the capacity to interact with a verified human has become a key differentiator, enabling companies to charge higher prices.
Adoption Challenges and Viability
While the structural drivers of the anti-AI movement are established, its long-term success faces several challenges that will influence its integration into global commerce over the next decade.
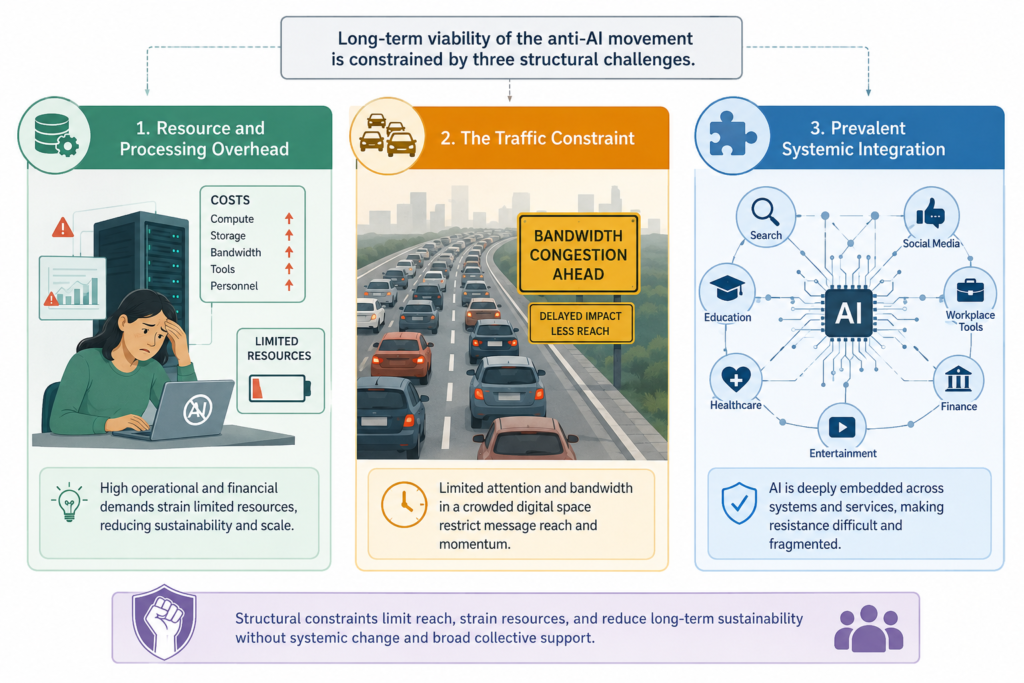
The long-term viability of the anti-AI movement is constrained by three structural challenges.
Resource and Processing Overhead: Defensive data poisoning via Glaze and Nightshade necessitates substantial local GPU power. Applying style cloaking to a single high-resolution portfolio can take several hours on consumer-grade hardware, rendering it impractical for independent creators lacking specialised systems.
The Traffic Constraint: Secure platforms like Cara have expanded rapidly by positioning themselves against automated data scraping. However, owing to their artist-centric nature, these platforms often struggle to attract non-artist consumers, art buyers, and commercial clients. This lack of commercial traffic limits monetisation opportunities, exerting financial pressure on artists to revert to mainstream platforms such as Instagram, despite their data harvesting policies.
Prevalent Systemic Integration: As major software providers such as Microsoft, Google, and Apple integrate generative AI directly into their operating systems, maintaining a purely “AI-free” workflow is becoming increasingly challenging. This deep integration blurs the distinction between traditional computing and generative automation, complicating the enforcement of human-only standards in the workplace.
Despite these challenges, the anti-AI movement is unlikely to vanish as a temporary trend in the future. It is evolving into a structured, institutional force that establishes a clear roadmap for the digital economy.
Conclusion

The anti-AI movement has evolved from small, local protests into a cohesive and organised entity. Initially, local strategies, such as mathematical image poisoning, were easily detected and countered by systems such as LightShed. The emergence of generative artificial intelligence (AI), also poses a threat by permanently altering human neural pathways, diminishing critical thinking, and fostering widespread intellectual complacency. The anti AI movement has fortified its defences through the implementation of advanced routing systems, state laws concerning likeness, and collective copyright lawsuits. The era of unrestricted web scraping is concluding, influenced by substantial settlements, exemplified by Bartz v. Anthropic and stringent transparency regulations imposed by the EU AI Act. This evolving legal landscape compels developers of generative tools to employ approved and licenced data models in their work. Concurrently, the market is adjusting to the pervasive use of synthetic media by placing a greater value on human-produced content. The “Human Premium” content market, underpinned by blockchain registries and rigorous verification standards, positions human-created work as a high-value, and secure alternative to automated outputs. Ultimately, the anti-AI movement marks out a distinct division within the digital economy: a high-volume, low-cost automated sector contrasted with a verified, legally protected, and premium-priced human sector.